*Project Core Members: Dr. Akshay Chaudhari (Discord: asc#2249), Dr. Christian Bluethgen (Discord: cblue#8445), Pierre Chambon (Discord: Pierre Chambon#4972) *****
Industry Collaborators: Stanford AIMI
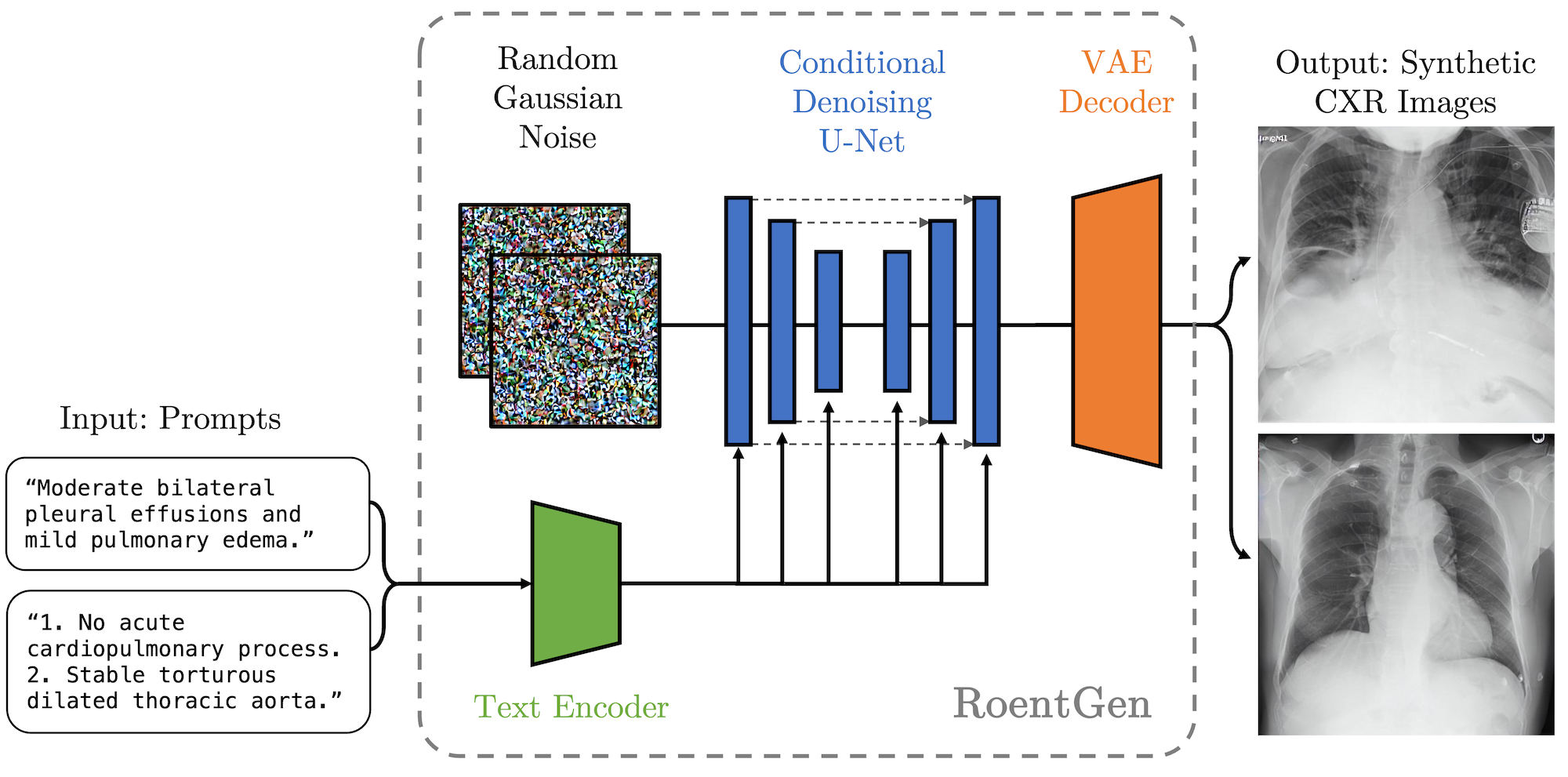
Multimodal models, trained on large datasets of natural image-text pairs, can generate high quality images controlled through text prompts. However, they are expected to work less well in the medical imaging domain as medical images and the language used to describe them are fundamentally different from natural images. To address this problem, a strategy is developed to adapt a pre-trained model by using medical images and their corresponding reports as a dataset. The goal of this proposal is to explore developing such foundational models for radiology image generation. We seek to determine the generative quality of such models as well as the downstream clinical utility that it could provide. The effectiveness of this adapted model will be evaluated through both quantitative metrics and expert radiologist assessments. Successful completion of this project may provide the possibility of reducing the need for cumbersome annotations of medical images for building data-efficient medical imaging models.
We have currently released our preliminary results as an arXiv preprint:
RoentGen: Vision-Language Foundation Model for Chest X-ray Generation